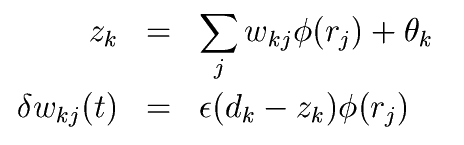3.4. Redes de funcion de base radial (RBF)
Este tipo de redes se caracteriza por tener un aprendizaje o entrenamiento híbrido. La arquitectura de estas redes se caracteriza por la presencia de tres capas: una de entrada, una única capa oculta y una capa de salida.
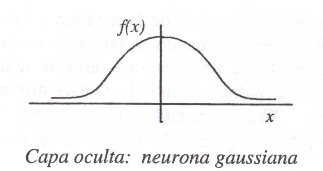
Aunque la arquitectura pueda recordar a la de un MLP, la diferencia fundamental está en que las neuronas de la capa oculta en vez de de calcular una suma ponderada de las entradas y aplicar una sigmoide, estas neuronas calculan la distancia euclídea entre el vector de pesos sinápticos (que recibe el nombre en este tipo de redes de centro o centroide) y la entrada (de manera casi analoga a como se hacia con los mapas SOM) y sobre esa distancia se aplica una función de tipo radial con forma gaussiana.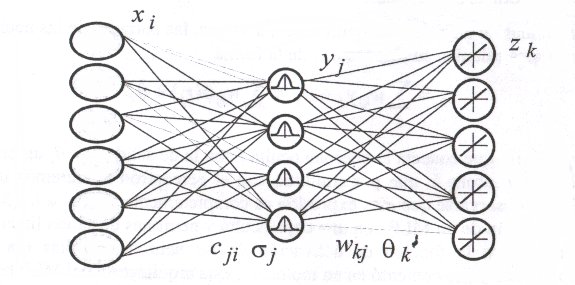
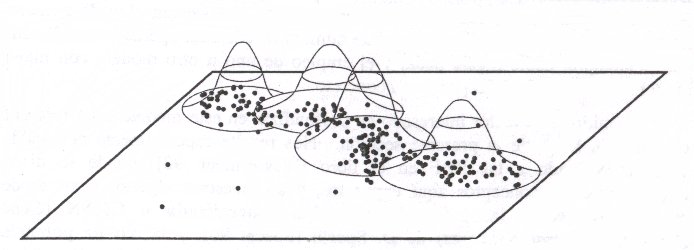
Para el aprendizaje de la capa oculta, hay varios métodos, siendo uno de los más conocidos el algoritmo denominado k-medias (k-means) que es un algoritmo no supervisado de clustering. k es el número de grupos que se desea encontrar, y se corresponde con el número de neuronas de la capa oculta, que es un parámetro que hay que decidir de antemano. El algoritmo se plantea como sigue:
Inicializar los pesos (los centros) en el instante inicial. Una incializacion típica es la denominada k-primeras mediante la cual los k centros se hacen iguales a las k primeras muestras del conjunto de datos de entrenamiento {xp}p=1..N
c1 = x1 , c2 = x2 , ... cN = xN ,
En cada iteracion, se calculan los dominios, es decir, se reparten las muestras entre los k centros. Esto se hace de la siguiente manera: Dada una muestra xj se calcula las distancias a cada uno de los centros ck. La muestra pertenecera al dominio del centro cuya distancia calculada sea la menor
Se calculan los nuevos centros como los promedios de los patrones de aprendizaje pertenecientes a sus dominios. Viene a ser como calcular el centro de masas de la distribución de patrones, tomando que todos pesan igual.
Si los valores de los centros varían respecto a la iteración anterior se vuelve al paso 2, si no, es que se alcanzó la convergencia y se finaliza el aprendizaje
Finalmente, se entrena la capa de salida. El entrenamiento de esta capa se suele usar un algoritmo parecido al que se usa para la capa de salida del MLP. La actualizacion de los pesos viene dada por la expresión:
Con este fin se suele presentar todos los patrones de la muestra de entrenamiento varias veces. Cada una de estas veces recibe el nombre de epoca.